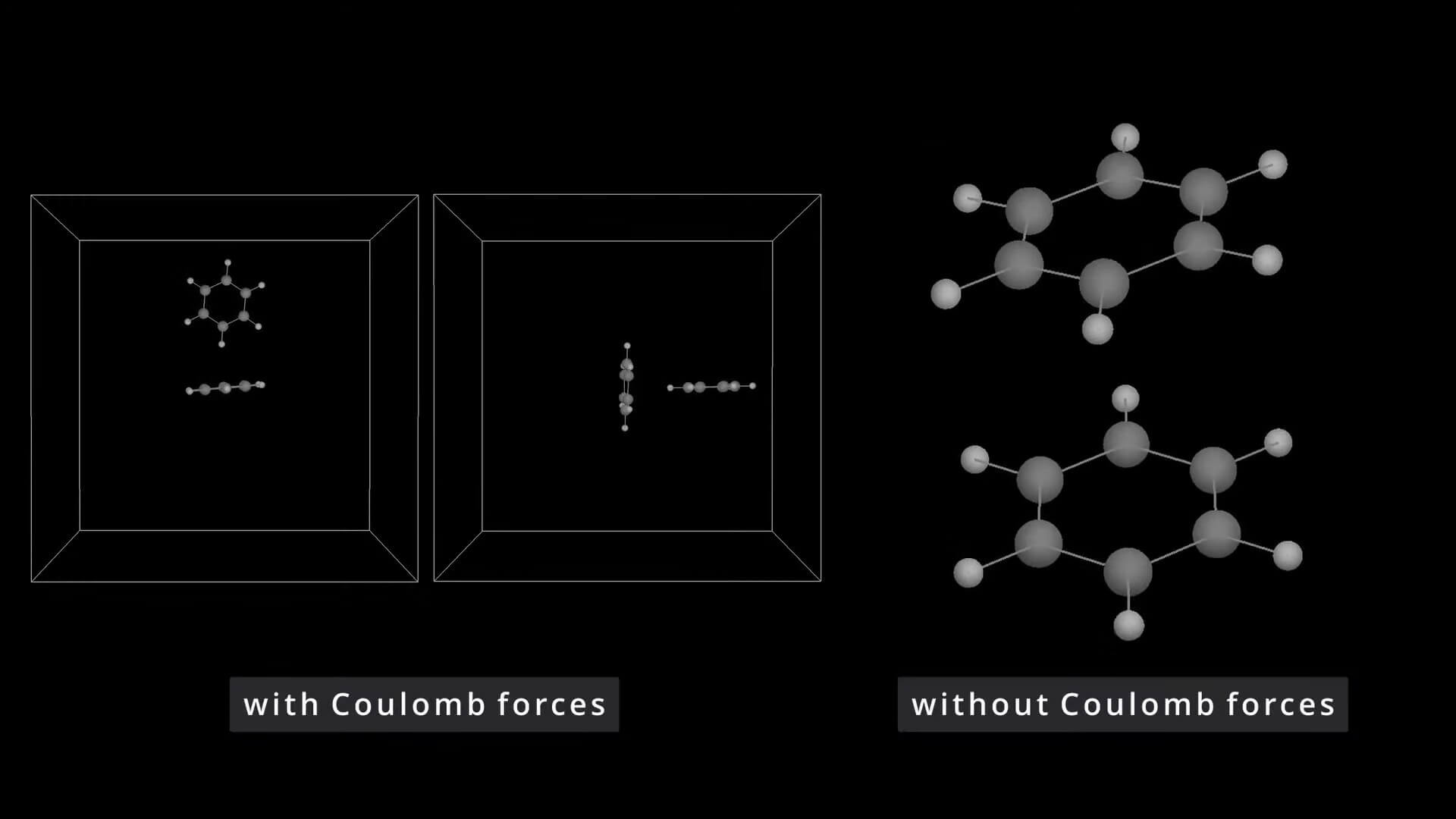
One of the last lectures for my master’s degree was on numerical simulation in molecular dynamics. For the examination project I developed a GPU MD code capable of reproducing certain preferred configurations the benzene dimer.
Today my first paper on implicit propagation in directly addressed grids was accepted for publication in Concurrency and Computation. It will soon be available as open access under DOI 10.1002/cpe.7509.
In other news, the annual report of our cluster usage Advances in Computational Process Engineering using Lattice Boltzmann Methods on High Performance Computers for Solving Fluid Flow Problems was accepted for publication in the annual proceedings on High Performance Computing in Science and Engineering by the High Performance Computing Center Stuttgart (HLRS). In this context I was also offered the opportunity of presenting it in person at the 25th Results and Review Workshop.
If you are interested in more details along those lines, I will give a talk on Lattice Boltzmann Performance Engineering in OpenLB at the Helmholtz HiRSE seminar on December 1st.
Today we released OpenLB 1.5 which marks a major step forwards by including both support for usage of GPUs and for vectorization on CPUs. These performance focused improvements are the result of major refactoring efforts that spanned both a significant fraction of my time as a student and most of my first months as a doctoral student.
For some further information check out the performance section of the OpenLB website. A recent video augments this by some pretty visuals produced on HoreKa’s GPU partition.
Today I submitted the full paper of my talk at the 32nd ParCFD conference for publication.
There we consider the LBM algorithm’s propagation step as a transformation of the space filling curve used as the memory bijection. Specifically, a neighborhood distance invariance property is utilized to derive the existing Shift-Swap-Streaming (SSS) scheme as well as a new Periodic Shift (PS) pattern.
A special focus is placed on SIMD friendly implementation via virtual memory mapping on both CPU and GPU targets.
Both patterns are evaluated in detailed benchmarks. PS is found to provide consistent bandwidth-related performance while imposing minimal restrictions on the collision implementation.
The preprint is available on Researchgate as well as directly (PDF).
One of the last lectures for my master’s degree was on numerical simulation in molecular dynamics. For the examination project I developed a GPU MD code capable of reproducing certain preferred configurations the benzene dimer.
For my seminar talk I wrote another LBM solver as a literate Org-document using CUDA and SymPy. The main focus was on just-in-time volumetric visualizations of the simulations performed by this code. While this is not ready to publish yet, check out the following impressions:

Further videos are available on my YouTube channel. e.g. a Taylor-Couette flow:

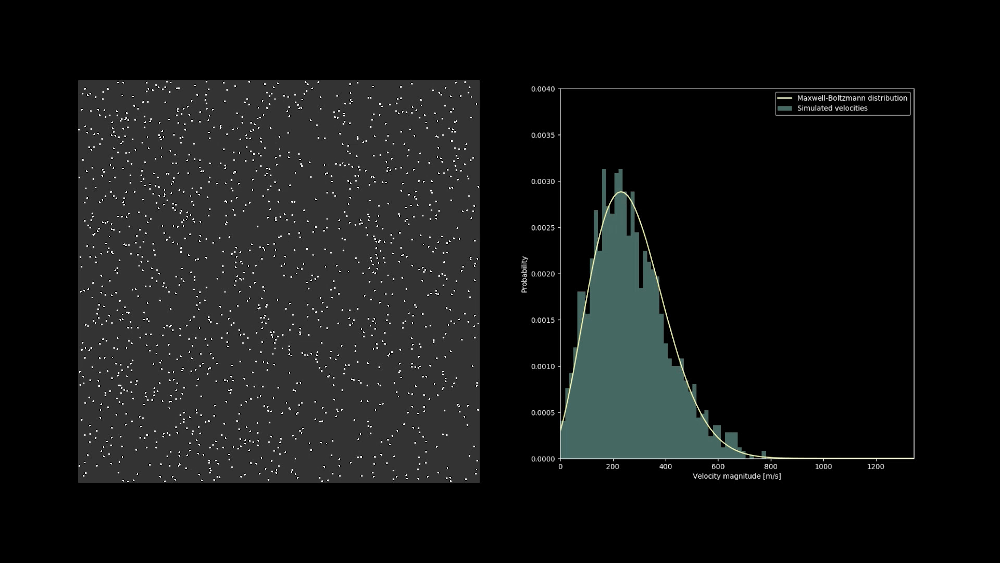
The velocity distribution of a system of colliding hard sphere particles quickly evolves into the Maxwell-Boltzmann distribution. One example of this surprisingly quick process can be seen in the following video:
The primary color of the sky is caused by Rayleigh and Mie scattering of light in the atmosphere. While attending the lecture on Mathematical Modelling and Simulation at KIT I implemented a ray marcher to visualize this. Together with a model for calculating the sun direction for given coordinates and times this allows for generating interesting plots:

For more details check out Firmament.
During the past exam season I now and then continued to play around with my GPU LBM code symlbm_playground. While I mostly focused on generating various real-time visualizations using e.g. volumetric ray marching, the underlying principle of generating OpenCL kernels from a symbolic description has not lost its promise.
This is why I have now started to extract the generator part of this past project into a more general framework. Currently boltzgen targets C++ and OpenCL using a shared symbolic description while providing various configuration options:
λ ~/p/d/boltzgen (boltzgen-env) ● ./boltzgen.py --help usage: boltzgen.py [-h] --lattice LATTICE --layout LAYOUT --precision PRECISION --geometry GEOMETRY --tau TAU [--disable-cse] [--functions FUNCTIONS [FUNCTIONS ...]] [--extras EXTRAS [EXTRAS ...]] language Generate LBM kernels in various languages using a symbolic description. positional arguments: language Target language (currently either "cl" or "cpp") optional arguments: -h, --help show this help message and exit --lattice LATTICE Lattice type (D2Q9, D3Q7, D3Q19, D3Q27) --layout LAYOUT Memory layout ("AOS" or "SOA") --precision PRECISION Floating precision ("single" or "double") --geometry GEOMETRY Size of the block geometry ("x:y(:z)") --tau TAU BGK relaxation time --disable-cse Disable common subexpression elimination --functions FUNCTIONS [FUNCTIONS ...] Function templates to be generated --extras EXTRAS [EXTRAS ...] Additional generator parameters
The goal is to build upon this foundation to provide an easy way to generate efficient code using a high level description of various collision models and boundary conditions. This should allow for easy comparision between various streaming patterns and memory layouts.
My recent experiments in using the SymPy CAS library for automatically deriving optimized LBM codes have now evolved to the point where a single generator produces both D2Q9 and D3Q19 OpenCL kernels.
Automatically deriving kernel implementations from the symbolic formulation of e.g. the BGK relaxation operator presents itself as a very powerful concept. This could potentially be developed to the point where a LBM specific code generator could produce highly optimized GPU programs tailored to arbitrary simulation problems.
Calculating the curl of our simulated velocity field requires an additional compute shader step. Handling of buffer and shader switching depending on the display mode is implemented rudimentarily for now. Most of this commit is scaffolding, the actual computation is more or less trivial:
const float dxvy = (getFluidVelocity(x+1,y).y - getFluidVelocity(x-1,y).y) / (2*convLength); const float dyvx = (getFluidVelocity(x,y+1).x - getFluidVelocity(x,y-1).x) / (2*convLength); setFluidExtra(x, y, dxvy - dyvx);
This implements the following discretization of the 2d curl operator:
Let be the simulated velocity field at discrete lattice points spaced by . We want to approximate the -component of the curl for visualization:
As we do not possess the actual function but only its values at a set of discrete points we approximate the two partial derivatives using a second order central difference scheme:
Note that the scene shader does some further rescaling of the curl to better fit the color palette. One issue that irks me is the emergence of some artefacts near boundaries as well as isolated “single-cell-vortices”. This might be caused by running the simulation too close to divergence but as I am currently mostly interested in building an interactive fluid playground it could be worth it to try running an additional smoothening shader pass to straighten things out.
The paper Automatic grid refinement criterion for lattice Boltzmann method by Lagrava et al. describes a criterion for measuring the local simulation quality using a comparison of the theoretical Knudsen number and the quotient of the cells’s non-equilibrium and equilibrium function.
While this criterion was developed to enable automatic selection of areas to be refined, it also offers a interesting and unique perspective on the fluid structure.
As the criterion requires calculation of the modeled Reynolds-, Mach- and Knudsen-numbers I took the time to set up the basics for scaling the simulation to actually model a physical system. Or rather calculating which physical model is represented by the chosen resolution and relaxation time.
In addition to the PDF (German, ~60 pages) all sources including any referenced simulation data are available on Github and cgit. The resulting actual implementation of the grid refinement method by Lagrava et al. in OpenLB is currently not available publicly and likely wont make it into the next release. Nevertheless – if you are interested in the code and I have not yet found the time to release a rebased patch for the latest OpenLB release don’t hesitate to contact me.
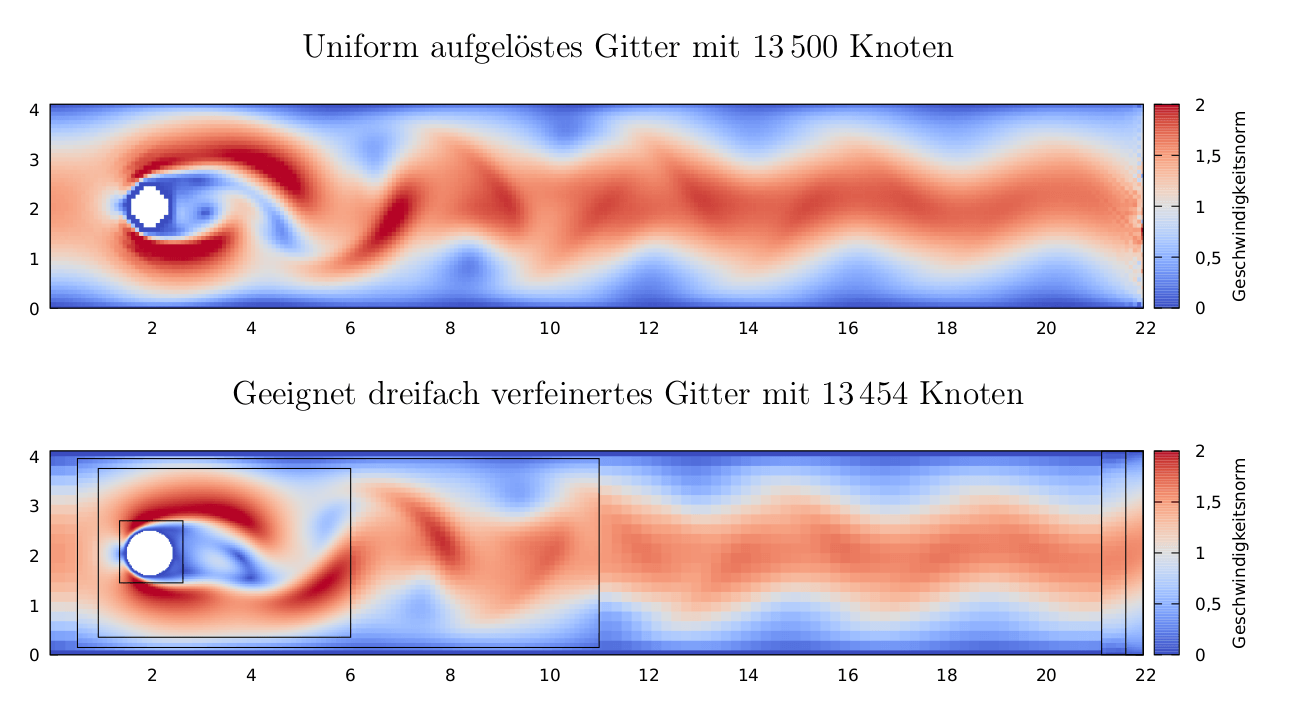
As a side note: The gnuplot-based setup for efficiently transforming Paraview CSV exports into plots such as the one above (i.e. plots that are neither misaligned Paraview screenshots nor overlarge PDF-reader-crashing PGFPlots figures) might be of interest even if one doesn’t care about grid refinement or Lattice Boltzmann Methods (which would be sad but to each their own :-)).
I found some time to further develop my GLSL compute shader based interactive LBM fluid simulation previously described in Fun with compute shaders and fluid dynamics. Not only is it now possible to interactively draw bounce back walls into the running simulation but performance was greatly improved by one tiny line:
glfwSwapInterval(0);
If this function is not called during GLFW window initialization the whole rendering loop is capped to 60 FPS – including compute shader dispatching. This embarrassing oversight on my part caused the simulation to run way slower than possible.
Replaces short-term Gitea instance on code.kummerlaender.eu.
The main reason for implementing this more complex setup is that Gitea both lacks in features in areas that I care about and provides distracting features in other areas that I do not use.
e.g. Gitea provides multi-user, discussion and organization support but doesn’t provide Atom feeds which are required for Overview.
This is why exposing gitolite-managed repositories via cgit is a better fit for my usecases.
Note that gitolite is further configured outside of Nix through its own admin repository.
As a side benefit pkgs.kummerlaender.eu now provides further archive formats of its Nix expressions which simplifies Nix channel usage.
Building the website in the presence of the Nix package manager is now as simple as:
shell.nixgeneratepreview to spawn a webserver in target/99_resultAll dependencies such as the internal InputXSLT, StaticXSLT and BuildXSLT modules as well as external ones such as KaTeX and pandoc are built declaratively by Nix.