» Published my BSc thesis on grid refined LBM in OpenLB
March 26, 2019 at 20:23 | grid_refinement_bsc_thesis | e4ba16 | Adrian KummerländerIn addition to the PDF (German, ~60 pages) all sources including any referenced simulation data are available on Github and cgit. The resulting actual implementation of the grid refinement method by Lagrava et al. in OpenLB is currently not available publicly and likely wont make it into the next release. Nevertheless – if you are interested in the code and I have not yet found the time to release a rebased patch for the latest OpenLB release don’t hesitate to contact me.
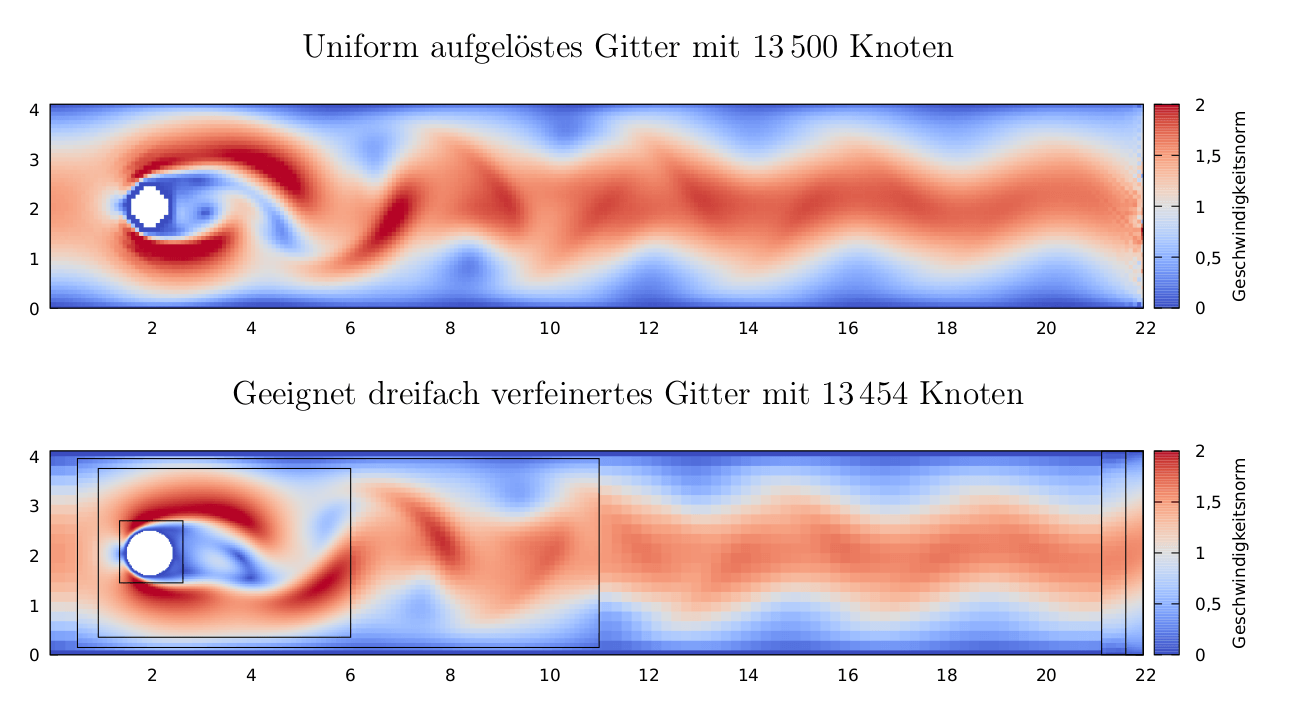
As a side note: The gnuplot-based setup for efficiently transforming Paraview CSV exports into plots such as the one above (i.e. plots that are neither misaligned Paraview screenshots nor overlarge PDF-reader-crashing PGFPlots figures) might be of interest even if one doesn’t care about grid refinement or Lattice Boltzmann Methods (which would be sad but to each their own :-)).
» Compustream performance improvements and interactive wall drawing
February 25, 2019 at 22:08 | compustream | 846665 | Adrian KummerländerI found some time to further develop my GLSL compute shader based interactive LBM fluid simulation previously described in Fun with compute shaders and fluid dynamics. Not only is it now possible to interactively draw bounce back walls into the running simulation but performance was greatly improved by one tiny line:
glfwSwapInterval(0);
If this function is not called during GLFW window initialization the whole rendering loop is capped to 60 FPS – including compute shader dispatching. This embarrassing oversight on my part caused the simulation to run way slower than possible.
» Describe custom gitolite and cgit setup
October 1, 2018 at 08:26 | nixos_system | 55daf8 | Adrian KummerländerReplaces short-term Gitea instance on code.kummerlaender.eu.
The main reason for implementing this more complex setup is that Gitea both lacks in features in areas that I care about and provides distracting features in other areas that I do not use.
e.g. Gitea provides multi-user, discussion and organization support but doesn’t provide Atom feeds which are required for Overview.
This is why exposing gitolite-managed repositories via cgit is a better fit for my usecases.
Note that gitolite is further configured outside of Nix through its own admin repository.
As a side benefit pkgs.kummerlaender.eu now provides further archive formats of its Nix expressions which simplifies Nix channel usage.
» Nixify build process
June 4, 2018 at 21:12 | blog.kummerlaender.eu | c08fbb | Adrian KummerländerBuilding the website in the presence of the Nix package manager is now as simple as:
- cloning this repo
- entering the nix-shell environment declared by
shell.nix - calling
generate - optionally call
previewto spawn a webserver intarget/99_result
All dependencies such as the internal InputXSLT, StaticXSLT and BuildXSLT modules as well as external ones such as KaTeX and pandoc are built declaratively by Nix.
» Implement particle trails using overlaying textures
May 23, 2018 at 19:06 | computicle | 84bcd4 | Adrian Kummerländer» Implement deferred word, conditional resolution
April 13, 2017 at 21:51 | slang | d2126f | Adrian KummerländerDue to the non-trivial way tokens were previously processed the compiler could not safely perform tail-call elimination. Thus the slang evaluation depth was restricted by the maximum call stack size.
This issue is mitigated by introducing deferred word resolution - i.e. pushing expanded tokens onto a buffer stack and processing them in an explicit loop.
This change ties into the implementation of the language’s conditional primitive. The previous implementation did implicitly not support direct nesting of conditional expressions such as:
truthA if
mainBranch
truthB if
secondaryMainBranch
then else
then
alternativeBranch
else
This issue is now made explicit by disallowing direct nesting of conditionals as depicted above. Appropriate exceptions are generated when required and the conditional primitive is reimplemented in a more robust fashion under the assumption that this rule holds. Note that nesting is still fully supported iff. the nested conditional is contained in a deferredly evaluated word. As a positive side effect this will make it slightly harder to generate unreadable code by forcing developers to write simpler words.
The main change of the conditional primitive lies in deferring branch token processing until the conditional expression is concluded by else. This is achieved by capturing non-dropped tokens in an internal buffer akin to how the word definition operator § is implemented. The branch buffer is discharged after else is evaluated. Discharging is triggered via the newly introduced result method of the primitive evaluation module. This avenue for injecting tokens into the processing stream may be used by further primitives in the future.