» Publications and talks
October 24, 2022 at 11:12 | Adrian KummerländerToday my first paper on implicit propagation in directly addressed grids was accepted for publication in Concurrency and Computation. It will soon be available as open access under DOI 10.1002/cpe.7509.
In other news, the annual report of our cluster usage Advances in Computational Process Engineering using Lattice Boltzmann Methods on High Performance Computers for Solving Fluid Flow Problems was accepted for publication in the annual proceedings on High Performance Computing in Science and Engineering by the High Performance Computing Center Stuttgart (HLRS). In this context I was also offered the opportunity of presenting it in person at the 25th Results and Review Workshop.
If you are interested in more details along those lines, I will give a talk on Lattice Boltzmann Performance Engineering in OpenLB at the Helmholtz HiRSE seminar on December 1st.
» Released OpenLB 1.5
April 14, 2022 at 12:00 | Adrian KummerländerToday we released OpenLB 1.5 which marks a major step forwards by including both support for usage of GPUs and for vectorization on CPUs. These performance focused improvements are the result of major refactoring efforts that spanned both a significant fraction of my time as a student and most of my first months as a doctoral student.
For some further information check out the performance section of the OpenLB website. A recent video augments this by some pretty visuals produced on HoreKa’s GPU partition.
» Submitted my first paper
August 4, 2021 at 15:30 | Adrian KummerländerToday I submitted the full paper of my talk at the 32nd ParCFD conference for publication.
There we consider the LBM algorithm’s propagation step as a transformation of the space filling curve used as the memory bijection. Specifically, a neighborhood distance invariance property is utilized to derive the existing Shift-Swap-Streaming (SSS) scheme as well as a new Periodic Shift (PS) pattern.
A special focus is placed on SIMD friendly implementation via virtual memory mapping on both CPU and GPU targets.
Both patterns are evaluated in detailed benchmarks. PS is found to provide consistent bandwidth-related performance while imposing minimal restrictions on the collision implementation.
The preprint is available on Researchgate as well as directly (PDF).
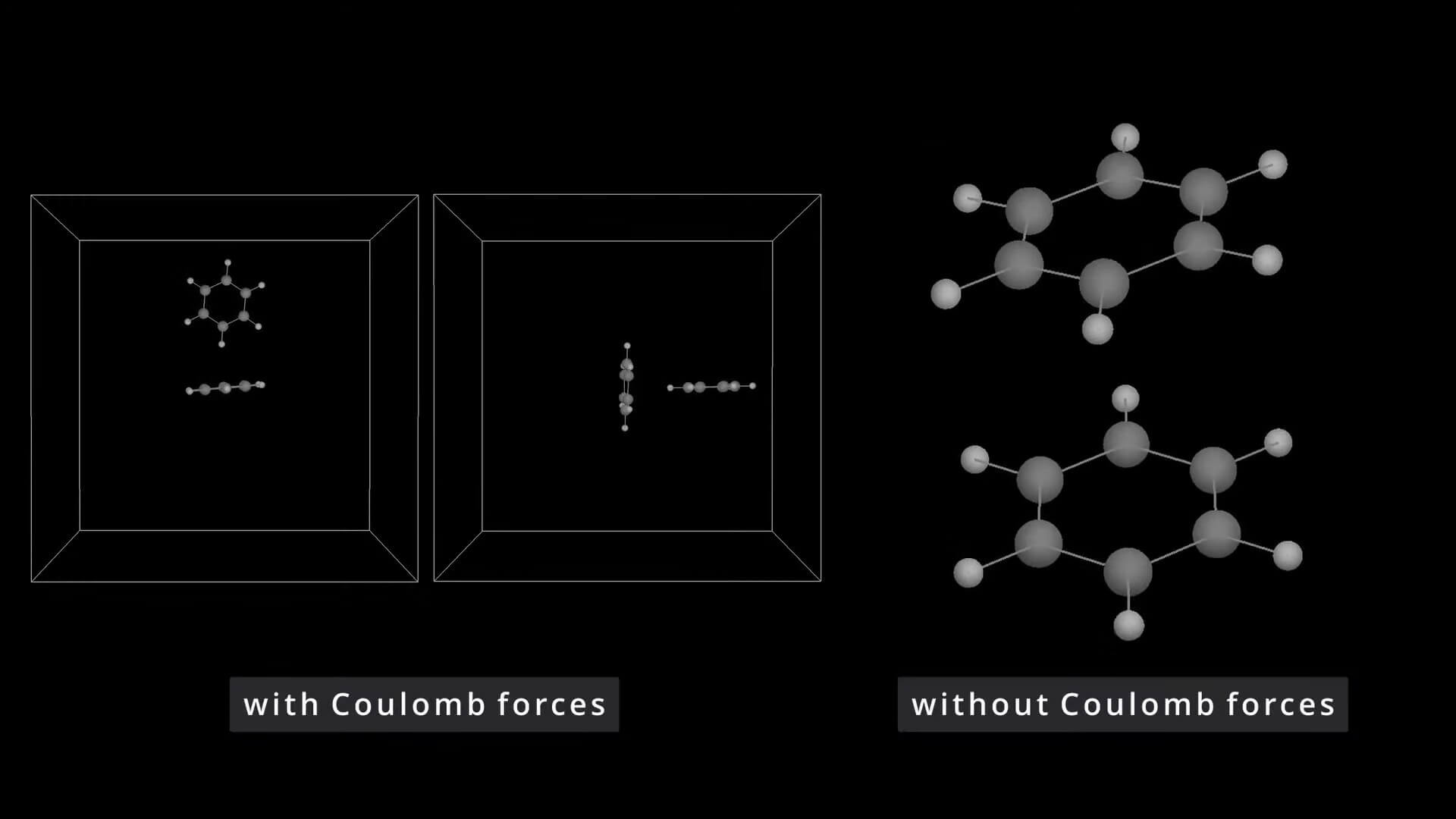
» Molecular Dynamics Simulation of the Benzene Dimer
March 31, 2021 at 20:05 | Adrian KummerländerOne of the last lectures for my master’s degree was on numerical simulation in molecular dynamics. For the examination project I developed a GPU MD code capable of reproducing certain preferred configurations the benzene dimer.
» Just-in-time volumetric CFD visualization
July 24, 2020 at 14:15 | Adrian KummerländerFor my seminar talk I wrote another LBM solver as a literate Org-document using CUDA and SymPy. The main focus was on just-in-time volumetric visualizations of the simulations performed by this code. While this is not ready to publish yet, check out the following impressions:

Further videos are available on my YouTube channel. e.g. a Taylor-Couette flow:

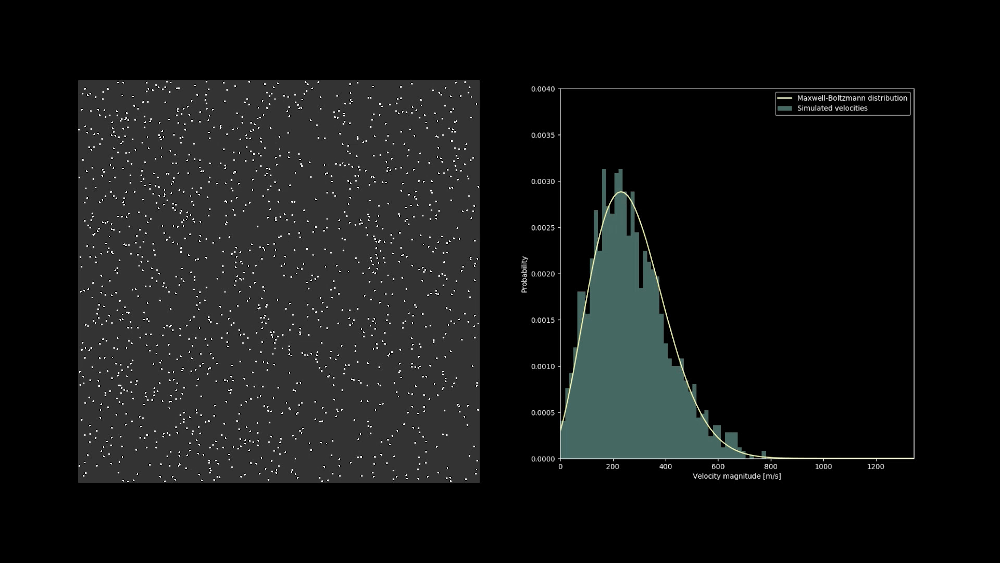
» Visualizing the velocity distribution of a hard sphere gas
March 24, 2020 at 21:42 | Adrian KummerländerThe velocity distribution of a system of colliding hard sphere particles quickly evolves into the Maxwell-Boltzmann distribution. One example of this surprisingly quick process can be seen in the following video: